
笔试合集
1、宏定义printf()
问题提出
有时候我们想用宏定义来决定是编译debug版本的代码还是release的代码,dubug版本的代码会通过printf打印调试信息,release版本的代码则不会。我们总不能对每一条printf都这样写:
1 |
|
解决方法
我后来想到一个方法,可以使用宏定义代替printf函数,由于printf是可变参数的函数,这里就要用到变參宏(…和__VA_ARGS__)。
在头文件下写此代码
后面需要打印调试信息的时候使用PR宏就可以了,如果需要release版本,不打印调试信息,就把DEBUG设置为0,编译出来的程序就不会打印调试信息了。
1 |
|
2、static的作用
1、修饰局部变量–静态局部变量
被static修饰的局部变量 只会被初始化一次,不会被改变,下一次使用该变量的值就是上一次的值
1 | void test(void) |
2、修饰全局变量–静态全局变量
也是被初始化一次,在当前模块中使用,不可以被extern引用
3、修饰函数–静态函数
经static修饰后不可跨文件调用函数,并报错。
3、linux操作系统是怎么启动的
1、硬件初始化
首先进行的是硬件初始化。
- 检测并初始化 CPU:CPU 是计算机的核心部件,它的初始化工作主要包括设置 CPU 的工作模式、时钟频率等参数。
- 检测并初始化内存:内存是计算机的临时存储空间,它的初始化工作主要包括为内存分配物理地址空间、设置内存的工作模式等。
- 检测并初始化硬盘:硬盘是计算机的主要存储设备,它的初始化工作主要包括检测硬盘的状态、设置硬盘的工作模式等。
- 检测并初始化键盘、鼠标等输入设备:这些设备是用户与计算机交互的主要工具,它们的初始化工作主要包括检测设备的状态、设置设备的工作模式等。
2、内核启动
硬件初始化完成后,计算机会加载并启动内核。内核启动的过程主要包括以下步骤:
- 从磁盘读取内核映像:内核映像包含了操作系统的所有代码和数据,它是通过磁盘上的文件系统提供的。
- 解压内核映像:内核映像通常以压缩的形式提供,需要解压后才能被内核读取。
- 跳转到内核入口点:内核入口点是一个特殊的函数,它是内核运行的起始点。当内核启动时,它会跳转到这个入口点开始执行。
3、系统初始化
内核启动后,接下来会进行系统初始化。系统初始化主要包括以下任务:
- 创建进程0(即 init 进程):init 进程是系统的主进程,它的任务是启动其他所有的进程。
- 初始化各种系统设备和服务:这包括网络接口、文件系统、设备驱动等。
4、文件系统挂载
系统初始化完成后,接下来的工作就是挂载文件系统。文件系统挂载是将文件系统与计算机的文件系统中的某个目录关联起来,使用户可以访问到文件系统中的内容。这一阶段主要完成以下任务:
- 确定文件系统的类型:文件系统有多种类型,如 ext2、ext3、ntfs 等,需要根据文件系统的类型来确定如何挂载。
- 确定挂载点的设备和挂载选项:挂载点是一个目录,需要确定这个目录的设备号和挂载选项。设备号决定了文件系统在哪个设备上挂载,挂载选项决定了如何访问文件系统中的内容。
- 挂载文件系统:根据前面的信息,挂载文件系统到指定的设备和挂载点。
5、登录提示符显示
文件系统挂载完成后,计算机会显示一个登陆提示符,提示用户可以登录操作系统了。此时,用户可以输入用户名和密码来登录操作系统
4、进程与线程的区别
一个进程由进程控制块、数据段、代码段组成
进程与线程的区别:
- 本质区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。
- 包含关系:一个进程至少有一个线程,线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
- 资源开销:每个进程都有独立的地址空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
- 影响关系:一个进程崩溃后,在保护模式下其他进程不会被影响,但是一个线程崩溃可能导致整个进程被操作系统杀掉,所以多进程要比多线程健壮。
优缺点总结:
1)一个进程死了不影响其他进程,一个线程崩溃很可能影响到它本身所处的整个进程。
2)创建多进程的系统花销大于创建多线程。
3)多进程通讯因为需要跨越进程边界,不适合大量数据的传送,适合小数据或者密集数据的传送。多线程无需跨越进程边界,适合各线程间大量数据的传送。并且多线程可以共享同一进程里的共享内存和变量。
进程间通讯:
(1)有名管道/无名管道(2)信号(3)共享内存(4)消息队列(5)信号量(6)socket
线程的通信:
(1)信号量(2)读写锁(3)条件变量(4)互斥锁(5)自旋锁
5、并行和并发的区别
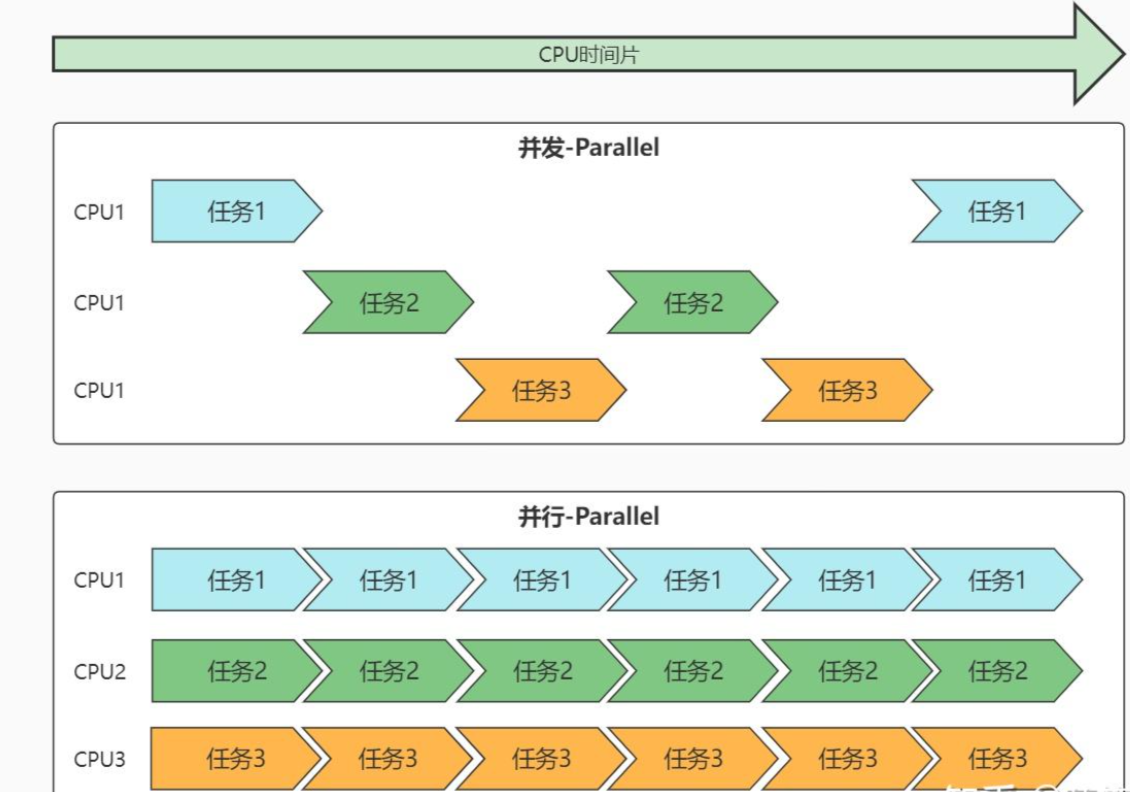
6、说明什么是上下文切换?
就是保存当前状态,切换任务,然后回到保存的状态
1、进程上下文
一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
2、中断上下文
一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
7、strcat、strncat、strcmp、strcpy 哪些函数会导致内存越界?如何改进?
strcpy函数会导致内存越界。
strcpy拷贝函数不安全,他不做任何的检查措施,也不判断拷贝大小,不判断目的地址内存是否够用。
1 | char *strcpy(char *strDest,const char *strSrc) |
strncpy拷贝函数,虽然计算了复制的大小,但是也不安全,没有检查目标的边界。
1 | strncpy(dest, src, sizeof(dest)); |
strncpy_s是安全的。
strcmp(str1,str2),是比较函数,若str1=str2,则返回零;若str1<str2,则返回负数;若str1>str2,则返回正数。(比较字符串)
strncat()主要功能是在字符串的结尾追加n个字符。
1 | char * strncat(char *dest, const char *src, size_t n); |
strcat()函数主要用来将两个char类型连接。例如:
1 | char d[20]="Golden"; |
8、strcpy和memcpy的区别
memcpy拷贝函数,它与strcpy的区别就是memcpy可以拷贝任意类型的数据,strcpy只能拷贝字符串类型。
memcpy 函数用于把资源内存(src所指向的内存区域)拷贝到目标内存(dest所指向的内存区域);有一个size变量控制拷贝的字节数;
1 | void *memcpy(void *dest, void *src, unsigned int count); |
就是说,memcpy是把整个内存拷过去,strcpy只可以拷贝字符串类型
9、const的用法
我记得有一个人说,不能把const当成常量,可以把他说成是只读。
- 用const修饰常量:不能被更改,相当于常量
- 用const修饰形参:func(const int a){};在当前函数中不能被更改,只能读不能写
- 用const修饰类成员函数:该函数对成员变量只能进行只读操作,就是const类成员函数是不能修改成员变量的数值的。
1 | const int *temp; // 指向常整型数的指针 只能操作指针,不能写值 |
10、volatile作用和用法
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量在内存中的值,而不是使用保存在寄存器里的备份(虽然读写寄存器比读写内存快)。
简单的来说,设置了volatile之后,编译器就不会对该变量进行优化。
这些情况一般会使用volatile:
- 并行设备的硬件寄存器(如:状态寄存器)
- 一个中断服务子程序中会访问到的非自动变量
- 多线程应用中被几个任务共享的变量
一般就是对寄存器的状态值、中断和多线程中的共享数据变量。
11、内存四区,什么变量分别存储在什么区域,堆上还是栈上。
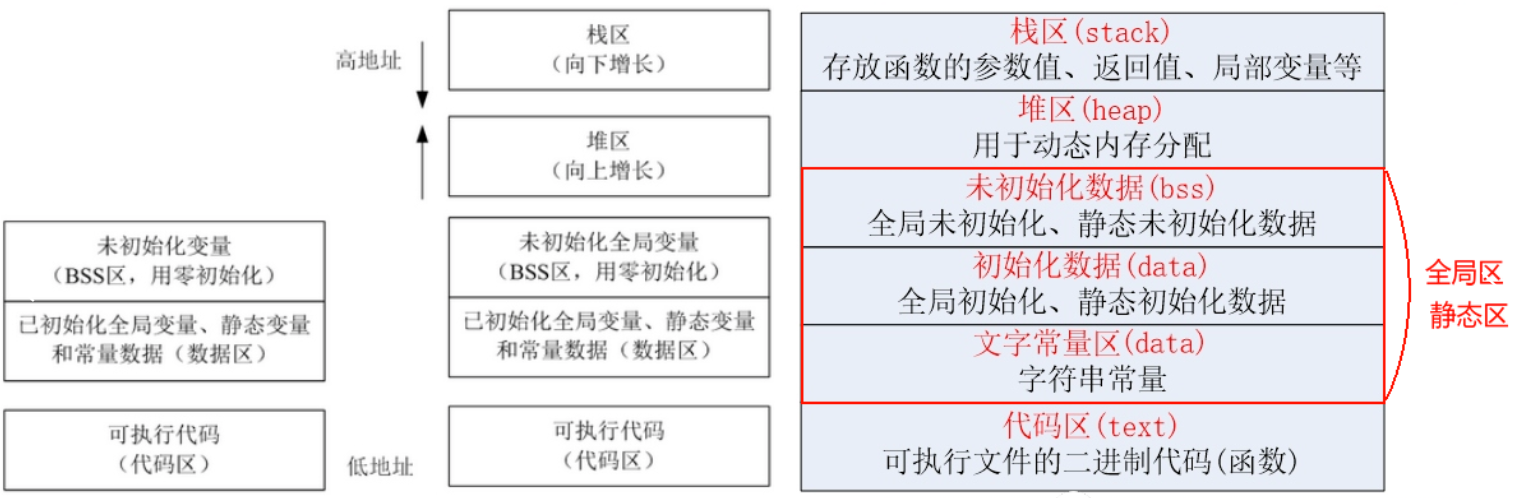
- 代码区(text segment):存放程序执行代码的区域,通常是只读的。该区域的内容在程序执行时不能被修改。
- 数据区(data segment):存放已经初始化的全局变量和静态变量(包括全局和静态变量的指针)的区域。
- BSS区(bss segment):存放未初始化的全局变量和静态变量的区域,该区域的值默认初始化为0。
- 栈区(stack segment):存放函数调用时的局部变量、函数参数和返回地址等信息。栈空间是由操作系统自动分配和回收的,它的大小通常是固定的,不能随意增加。栈空间是向下增长的,也就是说,栈顶的地址是越来越小的。
- 堆区(heap segment):存放由程序员手动申请的内存空间,大小可以动态增加或减少。堆空间是由程序员手动管理的,程序员需要负责在使用完毕后将其释放。堆空间是向上增长的,也就是说,堆顶的地址是越来越大的。
12、c语言编译的四个阶段
- 预处理阶段(Preprocessing):编译器会处理源文件,包括展开宏定义、头文件的展开、条件编译等,生成一个经过预处理后的文本文件。此阶段的结果是一个以 .i 为扩展名的文件。
- 编译阶段(Compilation):编译器将经过预处理的文本文件翻译成汇编代码。汇编代码是一种低级的、与机器相关的语言。此阶段的结果是一个以 .s 为扩展名的文件。
- 汇编阶段(Assembly):汇编器将汇编代码转换成机器可以执行的指令。此阶段的结果是一个以 .o 为扩展名的文件。
- 链接阶段(Linking):连接器将目标文件以及一些必要的库文件进行链接,生成可执行文件。此阶段的结果是一个没有扩展名的可执行文件。
13、请解释一下什么是中断,以及中断服务程序是如何工作的
就是打断当前正在执行的程序,去执行另一个程序,称为中断服务程序。中断可以由硬件设备或软件发起。
当一个中断被触发时,CPU会立即停止正在执行的程序,并保存当前的上下文信息。然后,CPU会跳转到中断服务程序的入口地址开始执行。中断服务程序会处理中断请求,并根据需要执行相应的操作,例如读取键盘输入、处理磁盘读写等。当中断服务程序执行完毕后,CPU会恢复之前保存的上下文信息,继续执行被打断的程序。
中断服务程序的工作流程包括以下几个步骤:
1、中断请求:硬件设备或软件发起中断请求。
2、中断响应:CPU立即停止正在执行的程序,保存当前的上下文信息,并跳转到中断服务程序的入口地址。
3、中断处理:中断服务程序处理中断请求,并根据需要执行相应的操作。
4、中断返回:中断服务程序执行完毕后,CPU恢复之前保存的上下文信息,继续执行被打断的程序。
14、TCP/IP协议
15、IIC和SPI协议
1、IIC协议
 wechat
wechat



